Can combining machine learning with DNA-encoded libraries revolutionize drug discovery?
Learn how drug hunters are leveraging advanced algorithms and DNA barcoding tools to bring targeted medicines to patients sooner
27 Oct 2022
Advances in computing power and the availability of large datasets are fueling a new era of drug discovery in which researchers can gain deep insights into millions of candidate compounds for a fraction of the cost of traditional screening methods. An emerging technique playing a critical role in this trend is the use of a DNA-encoded library (DEL). Using DELs, drug hunters can generate libraries containing billions of compounds, each traceable by a unique DNA tag, to use as a starting point for screening the best candidates against a specific drug target. Now, with the aid of revolutionary machine learning (ML) tools, this process is being further streamlined using algorithms to comb through these vast datasets, predict the best drug compounds, and even design downstream experiments to optimize their chances of clinical success.
One company making strides in this evolving field is Anagenex, where Senior Vice President, Joe Franklin, is leading the effort to harness the combined benefits of DEL technology and machine learning to identify new drug candidates faster and more efficiently than ever before. In this article, Franklin reveals how this approach is helping to solve long standing challenges in drug discovery, the importance of aligning screening tools with ML data needs, and what he sees for the future of computer-aided discovery. He also highlights the value of building strong relationships with suppliers of DEL components and shares why LGC Biosearch Technologies became Anagenex’s partner of choice in securing mission-critical oligonucleotides for its discovery platform.
Rapid screening at a lower cost
Anagenex is focused on tackling historically challenging drug targets, such as nucleic acid binding proteins, allosteric binding pockets, and proteins that require highly selective molecules to avoid toxicity. “There are a lot of proteins that have less than 5% total structural homology difference, so if you knock one out, it's highly likely that you're going to knock the other one out too,” explains Franklin. “These are the types of proteins we are looking at, including synthetic lethal cancer targets, where if you can selectively knock out one version and not the other, you can reduce toxicity and the tumor dies.”
To solve these selectivity issues, Franklin’s team employs an integrated computational and wet lab approach that relies upon the use of DNA-encoded library technology to test billions of compounds for binding to a particular drug target. “During DEL synthesis, small molecule compounds are made by combinatorial chemistry and encoded with unique DNA barcodes for each of the chemical synthesis steps,” explains Franklin. “This allows users to create unique labels for any possible set of chemistries and create billions of compounds in diverse libraries at a much lower cost than other screening technologies.”
All of this happens in just a single test tube. “One well or tube can be used to screen billions of molecules under one defined condition,” he remarks. “If you want to evaluate 25 conditions against your billions of molecules, you only need to set up 25 tubes.”
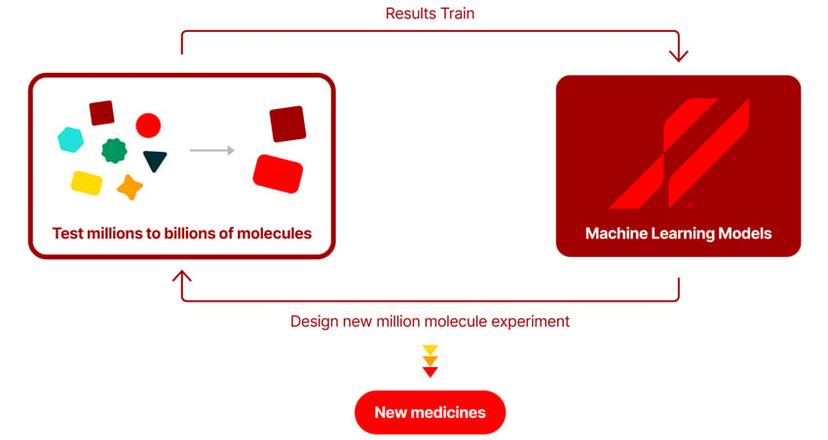
From an initial curated library of 2B possible drug compounds, Anagenex uses multiple parallel biochemical experiments to screen for promising candidates, with the results used to train proprietary machine learning models to understand what makes the best candidate compounds. These models then design new libraries of 1M or more compounds to be synthesized and tested. By iteratively running this loop of experimentation and machine learning, this approach generates increasingly robust predictions of drug-like compounds while optimizing candidate molecules to increase the likelihood that they will be successful in the clinic.
Combining DEL technology and machine learning

Whilst some drug discovery companies have been quick to apply machine learning tools to existing screening platforms, Anagenex’s platform is unique, in that it has been designed specifically to meet the dual needs of both technologies. “We designed a platform that focuses on what is important to machine learning and what is important to screening from the very beginning,” says Franklin. “We built them to work with each other – we haven't just bolted one on to the other.”
Generating large volumes of high-quality data is crucial to marrying these technologies. “We collect massive quantities of data at all steps of our DEL process, from library validation, library construction, target selections, and follow-up assays,” says Franklin, adding: “For example, every building block that goes into making one of our libraries gets validated against multiple substrates, and we use that information to better guide our machine learning. On the selection side, we look at many more conditions than other companies, conducting competition analyses, blocking active sites, and looking at allosteric sites and the difference between binding in an active site versus other sites on the protein. Our machine learning models have been purpose-built to incorporate and understand all this data to make highly accurate predictions against our targets.”
Sourcing high-quality components
DEL synthesis for drug discovery hinges on the reliable and timely procurement of large sets of chemical building blocks and customized oligonucleotides. Here, Franklin notes the benefits of working closely with trusted and quality-assured suppliers. “We have built relationships with key vendors that more resemble partnerships,” he says, adding: “On the building block side, we are collaborating with vendors to reduce the design, creation, testing, and analysis cycle, and have optimized parameters such as format and quantity to create faster turnaround times.”
We evaluated many different vendors but found that Biosearch Technologies provides us the best oligo quality for our process, and at the speed we need.
Joe Franklin Senior Vice President, Anagenex
When looking for providers of critical DEL oligo components, LGC Biosearch Technologies’ 35 years of experience in nucleic acid synthesis and wide offering of high-quality oligos in both standard and custom formats made it an obvious choice for Anagenex. “On the DNA side, all of our oligos come from LGC Biosearch Technologies,” he says, adding: “We evaluated many different vendors but found that Biosearch Technologies provides us the best oligo quality for our process, and at the speed we need. They also support our technology development with rapid turnaround.”
The future of drug discovery
DNA-encoded libraries and computational technologies are gaining ground in drug discovery, and Franklin sees them becoming even more integral to research efforts in the future. “Historically, datasets have been too small and computational tools too primitive to really make an enormous difference across the pipeline,” he says. “Now, more and more companies are generating large, high-quality datasets, using machine learning to understand those datasets, and then applying models to design new experiments to drive deeper and faster insights into what medicines might be successful.”
With this trend set to continue, the effective integration of computational and experimental approaches will also become increasingly important. “Companies that really understand how to combine lab work and computers effectively will be the most successful drug hunters in the future, and ultimately, this will lead to more and better drugs for patients,” he concludes.
Want to know more on this topic?
Join a live Q&A with Joe Franklin as he discusses the implementation of DEL technologies and coupling DEL with machine learning: Combining DNA encoded libraries with machine learning to accelerate drug discovery
Related Products
Request Quote for All Products
DNA encoded library (DEL) components
LGC Biosearch TechnologiesAccelerating drug discovery with better oligos

NxGen T4 DNA Ligase
LGC Biosearch TechnologiesA workhorse, high quality DNA ligase for joining blunt or cohesive ends of dsDNA or dsRNA.